Imagine AI as a Smart Student
Let's imagine AI is a student who has read millions of books.
When you ask a question, it doesn't search Google or remember an exact answer. Instead, it predicts what word should come next based on everything it learned during training.
That's the core idea behind Large Language Models (LLMs).
Step 1: Your Text Isn't Read as Words
Suppose you type:
How are you today?
Humans see four words.
But AI first converts this sentence into tokens.
Input Tokens vs Output Tokens
There are two important types of tokens.
Input Tokens
These are the tokens you send to the AI.
Example:
Explain AI simply.
This becomes input tokens.
The model reads these first.
Output Tokens
These are the tokens generated by the AI while answering.
For example,
AI is a technology that...
Every generated piece is an output token.
The AI predicts one output token at a time until it decides the answer is complete.
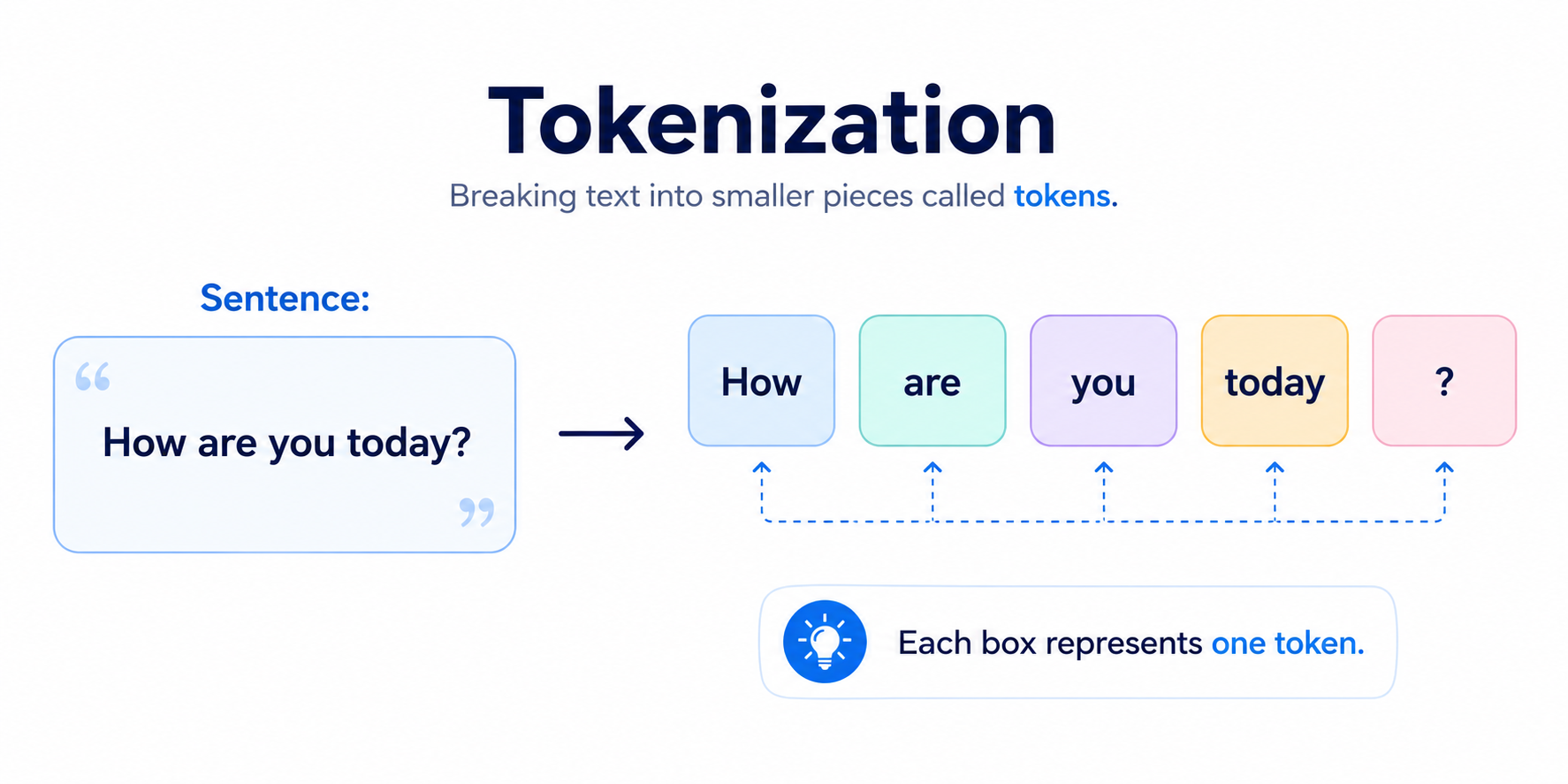
Step 2: Tokenization
The process of converting text into tokens is called Tokenization.
Think of it like cutting a long sentence into small puzzle pieces.
Sentence:
I love learning AI.
After tokenization:
["I", " love", " learning", " AI", "."]
Why is this necessary?
Because computers don't naturally understand words.
Breaking text into tokens makes it easier for AI to process language.
Step 3: Tokens Become Numbers
Computers don't understand words.
They only understand numbers.
So every token gets converted into a unique number.
For example,
"AI" → 4532
"learning" → 1289
Now the computer has numbers instead of words.
But these numbers still don't carry meaning.
That's where embeddings come in.
Step 4: Embeddings (Giving Meaning to Words)
An embedding is a mathematical representation of a word.
Instead of representing "cat" as simply a number like 23, AI converts it into hundreds or thousands of numerical values that capture its meaning.
Words with similar meanings end up close together.
For example,
King
Queen
Prince
Princess
will be located near each other.
Similarly,
Apple
Mango
Banana
will also be grouped together.
Imagine a huge map where similar words live in the same neighborhood.
That's essentially what embeddings create.
This allows AI to understand relationships between words instead of treating every word as completely unrelated.
Step 5: Positional Encoding (Understanding Order)
Imagine someone gives you these words:
home
going
I
am
You know the words, but the order is wrong.
The correct sentence is:
I am going home.
Without knowing the order, the sentence loses meaning.
Transformers don't naturally understand word order.
So they add something called Positional Encoding.
It tells the model where each token appears in the sentence.
For example,
I → Position 1
am → Position 2
going → Position 3
home → Position 4
Now AI understands both:
what each word means
where it appears
This helps it understand grammar and sentence structure.
Step 6: Self-Attention (The Secret Behind Modern AI)
This is one of the biggest innovations introduced in the Transformer architecture.
Let's take a sentence.
The cat sat on the mat because it was tired.
What does "it" refer to?
Humans immediately know that "it" means the cat.
AI has to figure this out.
Self-attention allows every word to look at every other word in the sentence and decide which ones are most important.
When processing the word "it," the model pays much more attention to "cat" than to "mat."
You can think of it like a student reading a paragraph.
Instead of reading one word at a time and forgetting the previous words, the student keeps looking back at the important words while understanding the sentence.
This ability to focus on relevant parts of the input is what makes modern AI much better than older language models.
The Transformer
All the concepts we've discussed—tokenization, embeddings, positional encoding, and self-attention—come together in an architecture called the Transformer.
The famous research paper "Attention Is All You Need" introduced this architecture in 2017, and it completely changed the field of Artificial Intelligence.
Today, many popular AI models are built on Transformer-based architectures.
Training: How AI Learns
Before AI can answer questions, it needs to learn.
This learning process is called training.
During training, the model is shown massive amounts of text from books, articles, websites, and other publicly available or licensed data sources.
The model repeatedly performs a simple task:
Predict the next token.
For example,
The sky is ______
It predicts:
blue
If the prediction is wrong, the model adjusts millions (or even billions) of internal parameters to improve.
This process happens billions of times.
Over time, the model becomes better at recognizing language patterns, grammar, reasoning, and relationships between ideas.
Training is computationally expensive and can take weeks or even months on thousands of powerful GPUs.
Labeling: Teaching AI with Correct Answers
Not all training data is automatically useful.
Sometimes humans help by labeling data.
For example,
Question:
What is 2 + 2?
Correct Answer:
4
Or,
Email:
"Congratulations! You won ₹10,00,000."
Label:
Spam
These labels teach the model what the correct output should be.
For chatbots, human reviewers may also compare multiple responses and indicate which one is more helpful, accurate, or safer. This feedback helps improve the model's behavior during later stages of training.
Inference: When You Chat with AI
Once training is complete, the model is ready to answer users.
This stage is called inference.
Here's what happens when you ask a question:
Your text is tokenized.
Tokens are converted into embeddings.
Positional information is added.
Self-attention analyzes relationships between tokens.
The model predicts the next token.
It repeats this process one token at a time until the response is complete.
Interestingly, the model isn't thinking several paragraphs ahead. It simply keeps predicting the most likely next token based on everything generated so far.
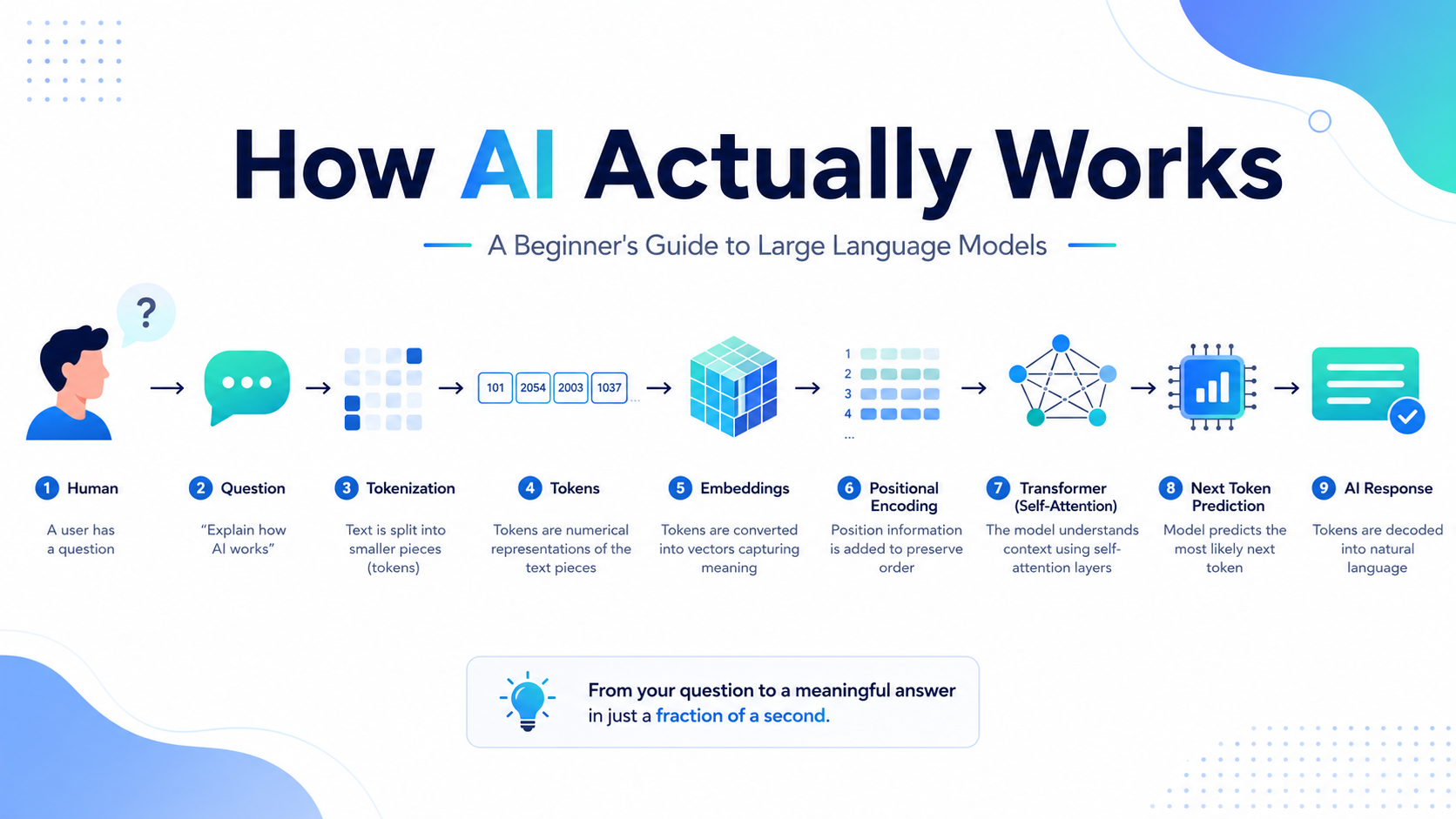
Putting It All Together
Let's see the complete journey.
You type a question
↓
Tokenization
↓
Tokens
↓
Embeddings
↓
Positional Encoding
↓
Self-Attention inside the Transformer
↓
Next Token Prediction
↓
Output Tokens
↓
Final Answer
Every response from an LLM follows this basic pipeline.
Final Thoughts
Before learning about Generative AI, I thought AI somehow "understood" language the way humans do. Now I realize it's a beautifully engineered system built from several simple ideas working together.
It starts by breaking text into tokens, converts those tokens into meaningful numerical representations, understands their positions and relationships using self-attention, and finally predicts the next token—again and again—until a complete response is formed.
Of course, this article simplifies many complex mathematical concepts. Topics like attention scores, query-key-value vectors, neural network layers, backpropagation, and optimization deserve their own deep dives.
But if you're just beginning your journey into Generative AI, understanding these building blocks is a great first step.
I'm excited to keep learning and share more as I explore this fascinating field.
References
Attention Is All You Need by Ashish Vaswani and colleagues.


